Hi cosors,
Thanks for posting this.
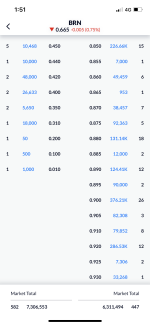
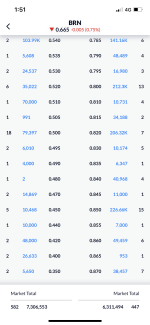
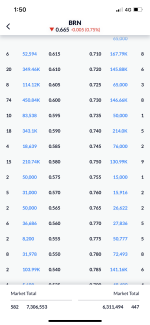
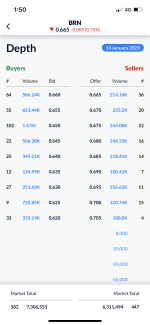
The Attention function requires a lot of multiplication:
"The first step in calculating self-attention is to create three vectors from each of the encoder’s input vectors (in this case, the embedding of each word). So for each word, we create a Query vector, a Key vector, and a Value vector. These vectors are created by multiplying the embedding by three matrices that we trained during the training process."
...
"The score is calculated by taking the dot product of the query vector with the key vector of the respective word we’re scoring."
...
"pass the result through a softmax operation. Softmax normalizes the scores so they’re all positive and add up to 1.
...
This softmax score determines how much how much each word will be expressed at this position. Clearly the word at this position will have the highest softmax score, but sometimes it’s useful to attend to another word that is relevant to the current word.
The fifth step is to multiply each value vector by the softmax score (in preparation to sum them up). The intuition here is to keep intact the values of the word(s) we want to focus on, and drown-out irrelevant words (by multiplying them by tiny numbers like 0.001, for example).
The sixth step is to sum up the weighted value vectors. This produces the output of the self-attention layer at this position (for the first word)."
Given that Akida avoids MAC operations in its 4-bit mode, I wonder if Akida can be configured to avoid one or more of these multiplication steps.
As far as I can make out, self-attention involves selecting important words (subject (noun), verb, and object (noun/adverb/adjective)) ... and sentences can be much more complex.
This describes the treatment of a short sentence. To obtain the context, it may be necessary to process a larger chunk of text, such as a whole paragraph. The mind boggles!


 www.linkedin.com
www.linkedin.com