Here's an article from late last year where this author does various reviews on companies, their strategies, Dev etc.
Had to split into 3 posts as too many characters.
He seems to have the same line of thinking as the rest of us as to what they need....guess it's just how they might go about it and implement

Covered in part 3 if want to skip analysis.
A pure strategic masterclass from Nvidia's trillion-dollar accelerated computing empire

www.howtheygrow.co
How Nvidia Grows: The Engine for AI and The Catalyst Of The Future
A pure strategic masterclass from Nvidia's trillion-dollar accelerated computing empire
 JARYD HERMANN
JARYD HERMANN
SEP 07, 2023
 Welcome to How They Grow, my newsletter’s main series. Bringing you in-depth analyses on the growth of world-class companies, including their early strategies, current tactics, and actionable product-building lessons we can learn from them.
Welcome to How They Grow, my newsletter’s main series. Bringing you in-depth analyses on the growth of world-class companies, including their early strategies, current tactics, and actionable product-building lessons we can learn from them.
Hi, friends
Get comfy, and hold onto your seats.
I won’t mince words here. Nvidia—the most valuable company by market cap that we’ve tackled so far—is not just a behemoth, but one of the most important companies on the planet. Analyzing a company this size means I’m either going to get caught with my pants down trying to tell this story well enough, or, if pulled off, I imagine this will be one of the more successful deep dives I’ve done.
As always, you’ll be the judge of that.

We all know Nvidia has taken the spotlight in the news recently, and for good reason. On the surface, it’s because their stock has been on an absolute tear.
Just take May 25th, when they added $184
billion to their market cap in a single day. That’s more than the value of SHEIN, Stripe, and Canva combined.

And it’s not just a price run with nothing behind it. In their latest second-quarter earning report, their revenue was $13.51 billion, up 101% YoY and up 88% from Q1. They also have $16B in cash/liquid assets. That’s wild.
Of course, this growth has been because Nvidia is playing a huge role in this AI revolution. But I don’t need to tell you that with a 30-year-old company valued at $1.2 trillion—there’s more to the story.
So, my curiosity sent me on a 30-hour researching and analyzing spree, going over everything I could get my hands on to bring you my armchair analysis of the world's 6th most valuable company.
I’ll summarize this 7K word deep dive for you in three words:
a strategic masterclass.
Jensen Huang—the Taiwanese-born, leather-jacket-rocking, and pimped-up-Toyota-Supra-driving founder and CEO of Nvidia—is a man who’s bet the entire future of Nvidia not once, but
three times. And, he may well do it again.
Jensen is a seismic wave-spotting genius, and arguably one of the best strategic executors I’ve come across. He has a resume of
making deep and accurate analyses of Nvidia’s competitive and macro environment, developing very clear and well-defined strategic visions, and addressing all potential strategic bottlenecks with policies and coherent actions that guide Nvidia forward.
But, there’s a good chance you’ve never heard his name until now because he doesn’t poke at other CEOs about cage-fighting, and he doesn’t get people all riled up. He thinks, strategizes, and he humbly gets to work building for the future.

Jensen Huang
I learned so much from studying him and Nvidia. I hope you will too.
Now,
just to tease what we’ll be getting much deeper into…
Nvidia’s invention of the Graphical Processing Unit in 1999 pioneered one of the most significant developments in modern technology:
GPU-accelerated computing. With it, they also sparked the growth of the PC gaming market, redefined modern computer graphics, and revolutionized parallel computing;
allowing computers to do way more.
In the past few years, Nvidia saw their first big growth surge with the crypto wave, where their computational hardware was essential for mining. But, after the hype cycle, revenue fell as crypto crashed and the gaming industry slummed.
Then along came ChatGPT, producing a tidal wave of interest in the AI sector, especially Generative AI. This ignited a race at various layers of the AI stack. While Google, Microsoft, Meta, OpenAI, Anthropic, and other AI players battle it out, Nvidia
rakes in the cash because their chips power pretty much all of them. And they’re benefiting from this increased demand more than anybody else because Nvidia’s specialized chips can process large amounts of data more efficiently and cost-effectively than traditional semiconductors. Essentially, they are the ground for AI research.
You might be thinking that Nvidia won the lotto here by having GPU chips so perfectly suited for being the engine behind AI. Except, thanks to Jensen, being in this position was a decade in the making. The company’s chips broke through the AI community back in 2012 with AlexNet Neural Network, and it’s clear Nvidia made a massive bet on AI long before other companies did. As Jensen said in a keynote at the National Taiwan University in May, “
We risked everything to pursue deep learnings.”
So, while Nvidia gets to ride the AI wave, it’s their GPU-powered deep learning that
actually ignited modern AI in the first place, with their GPUs acting as the brains of computers, robots, and self-driving cars.
Simply, through a pick-and-shovel play (more on this soon), Nvidia is tightly coupled with most high-growth sectors, like AI, machine learning, VR/AR, big data, cybersecurity, gaming, crypto, and autonomous travel, as they all rely on Nvidia’s chips. Thus, when one of these high-growth sectors is running hot, so too will Nvidia.
In short, Nvidia’s products are at the center of the most consequential mega-trends in technology. And I have no doubt that they will continue to be at the forefront of the next revolution. At the end of this piece, we’ll touch on what that might be for Nvidia:
Hint: Neuromorphic Computing. 
On
that note, let's get to it.

Here’s what you can expect in today’s analysis:
- How Nvidia Started: Denny’s Diner, Stumbled Steps, GPUs, and CUDA
- Right direction, wrong product
- Spotting an opportunity in gaming, crafting a winning GPU strategy, and building their base layer
- Expanding beyond games, and unlocking industries with the CUDA platform
- How They Grow: Powering The Next Stage Of The Internet
- The Nvidia Data Center: One platform, unlimited acceleration
- Chips & Systems: AIaaS— a classic Pick-and-Shovel play
- Nvidia Omniverse: The platform for the useful metaverse
- Seeding their own multi-market ecosystem: A lesson on expanding your TAM
- What could be next for Nvidia? Neuromorphic Computing?
How Nvidia Started: Denny’s Diner, Stumbled Steps, GPUs, and CUDA
The story of Nvidia is one that shows how engineering breakthroughs really do push our world forward.
There are a lot of places I could start telling it, but I think the most logical place is in a dingy diner covered in bullet holes, in the then-sketchy neighborhood of East San Jose, in April 1993. Three entrepreneurial electrical engineers—Jensen Huang, Chris Malachowsky, and Curtis Priem—sat drinking bottomless burnt coffee, deep in conversation, anticipating that the next wave of computing would be graphics-based.
Nobody would have thought their conversation about chips was laying the foundation for a company that was about to define computing—and still does.
As Chris recalled:
There was no market in 1993, but we saw a wave coming. There's a California surfing competition that happens in a five-month window every year. When they see some type of wave phenomenon or storm in Japan, they tell all the surfers to show up in California, because there's going to be a wave in two days. That's what it was. We were at the beginning.
The wave they saw coming was the nascent market for accessible GPUs, and how there was an opportunity to create plug-in chips for PCs that could provide realistic 3D graphics for games and films.
So, buzzed on coffee and their strong conviction that the next big opportunity in technology was in
accelerated computing— a parallel processing approach that frees the computer’s Central Processing Unit (CPU) and gives the heavy lifting of data processing to other processors, like the GPU—they left Denny’s Diner to go and found Nvidia.
Things were in motion. But it took a few years for them to find their feet.
Right direction, wrong product
Even though Jensen implemented a highly successful strategy from 1998 to 2008—setting their trajectory to own the global chip market— Nvidia stumbled in their first steps.
The first product they built was a multimedia card called NV1, which was introduced in the market in 1995.

The founders leaned on the expected multimedia revolution at the time and tried to ride the wave and establish an industry standard. However, the NV1 was a bit of a flop. It wasn’t considered better than the competitors (Intel, and AMD), and it was hard to program. As a result, the games that were created for the NV1 weren’t great and had performance issues.

They got to work on a second version, the NV2, but ended up canning it before it went live.
Why?
Because
they were not feeling a pull from the market, and while NV2 was in development, Jensen was running a strategic analysis that took into account the team’s, and company’s, existing strategic advantages, as well as crucial market observations from media industry experts like Ed Catmull, co-founder of Pixar.
He realized their current path was not the way, and he made the first big bet on Nvidia’s future.
So, four years in and with an actual product in the market paying the bills, he made a major strategic pivot and focused on the development of a product that he believed would be better suited for a new, exponentially growing, market.
Spotting an opportunity in gaming, crafting a winning GPU strategy, and building their base layer
Jensen and the team noticed an attractive opportunity in the field of 3D graphics, a sub-niche of their initial multimedia focus.
A good lesson on the exercise of niching down to find your sweet spot in the market. 

They decided this was the market they needed to focus on, the real wave, and set out to design a Graphic Processing Unit (GPU) that would render 3D graphics. They dropped their initial approach to graphics they had created with the NV1 and adopted the then quickly-rising (and today’s standard) in 3D graphics processing—
the graphics pipeline. This approach was in fact developed by a competitor, SGI.
So, why did the team decide to compete in this fast-paced and highly competitive arena of computational power? Why did they think this move would be successful? Two reasons:

1. The market’s demand for GPUs was expected to be “unlimited”
Unlimited in the sense that it would surpass supply by a significant margin and wouldn’t slow down anytime soon.
This meant there was a massive TAM and a big enough slice for Nvidia to take.
The reason was the emerging video game industry, where (1) games had the most computationally challenging problems, (2) computational processing power was a competitive advantage for online video gamers, and (3) they believed video there would be incredibly high sales volume.
So, the better your GPU as a gamer, the better your performance, and the more bragging rights you’d have about your gaming skills.
This presented gaming as a strong wedge into the 3D graphics computational arena—which as we’ll see—became the company's core flywheel to reach other adjacent markets and fund huge R&D to solve massive computational problems.
2. They took a radically different position in the computational market
Remember,
accelerated computing is all about improving a computer's processing power. The better it can process, the more advanced feats it can pull off. Back in the '90s and early 2000s, the main place processing was taking place was the PC's Central Processing Unit (CPU).
When Nvidia broke into this market, the main dog was Big Blue: Intel.
Intel's incumbent strategy was to minimize the CPU’s costs. AKA, to make the single horse pulling the chariot more efficient and more profitable to sell.
Nvidia’s strategy was to maximize the GPU’s performance. AKA, to add another type of workhorse to share the load. It increased the cost of the machine, but their go-to-market was to cater to the constantly growing need for faster graphics rendering.
To give a bit more context as to why Jensen’s bet was such an innovative and bold one, it’s helpful to understand the status quo at the time in the industry. In short,
progress in computational power depended on decreasing the size of transistors and reducing consumed power. So, the first chip player who found a way to design a significantly smaller transistor and a way to manufacture it would gain a huge advantage in the market.
Sounds good, except that the rate of progress seemed to follow an observation by Gordon Moore, Intel’s co-founder, known as
Moore’s law. It basically stated that significant progress in chips would occur every 2 years.
https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https://substack-post-media.s3.amazonaws.com/public/images/d0f2bdbe-c71f-4110-a2a1-3ab2e3fd43d0_1500x1000.png
The whole industry relied on that law, accepting that nobody could really break it. At least not consistently. Which is kind of funny when you think about it: the leader of the incumbent company coining a law that in a way fends off competition.

But, Nvidia’s radically different positioning in the computational arena was based on Jensen’s belief that Nvidia could actually provide an equivalent improvement of computational power in one-third of the industry’s cycle by focusing on increasing the number of transistors in their
GPUs (not CPUs), taking full advantage of the graphics pipeline approach.

This approach was revolutionary, and their GPU strategy was so successful at setting up Nvidia’s advantage for 2 big reasons:
- It enabled multiple lightning strikes within its category—driving big attention waves. Being able to announce a GPU that was 2 times as fast as the previous one, and 3X faster than competitors, meant they got a ton of large-scale marketing. This built their brand and allowed them to steal market share from Intel.
- It enabled them to build a data and experience flywheel much faster. Thanks to their ultra-fast iteration cycles, Nvidia’s team gained experience in how to turn their technological designs into sellable products three times faster than their competitors. And since the available human capital in the industry was limited, experienced engineers were another benefit that amplified Nvidia’s competitive advantage—a cornered resource superpower.
With this, Nvidia created and won the GPU category. They went public in 1999 at 82c a share. (Today, they’re up 59,000%), and from 2000 to 2008, this strategy quadrupled their revenue, allowing their R&D flywheel to solve more technical challenges in computing.
The first big bet that paid off.
But, unfortunately, the
physical limit in the chip world
does exist, as you can only make a transistor so small.
So, despite forking in the cash and watching their public company’s stock price climb, Jensen saw the limit approaching. He saw Nvidia losing their coveted advantage. And being a badass who never rests on his laurels, he went back to the strategy board and maneuvered the ship once again.
Expanding beyond games, and unlocking industries with the CUDA platform
From 1999 to 2006, Nvidia’s bread and butter was servicing the gaming market with their newly minted GPU hardware.
And this stage was foundational, not just for the company, but for human progress. Simply, because
GPUs set the stage to reshape the computing industry.
But in 2006, they opened Pandora’s box to
how GPUs could be used by launching
CUDA—a general-purpose programming model that allowed developers to use their Nvidia GPUs for other things.
This was Jensen and Nvidia’s
first platform strategy.
To drastically oversimplify it,
this made the power of accelerated computing fully accessible, allowing smart people to unlock and harness their GPU’s processing ability beyond games. This breakthrough allowed for multiple computations at a given time instead of sequentially, resulting in much faster processing speeds—
a game-changing move in the development of applications for various industries, like aerospace, bio-science research, mechanical and fluid simulations, climate modeling, finance, professional visualization, energy exploration, autonomous driving, and AI, which all require big number crunching to work.
In other words, CUDA was a monumental development in the industry that took Nvidia from a hardware product for gaming to
an industry-opening platform.
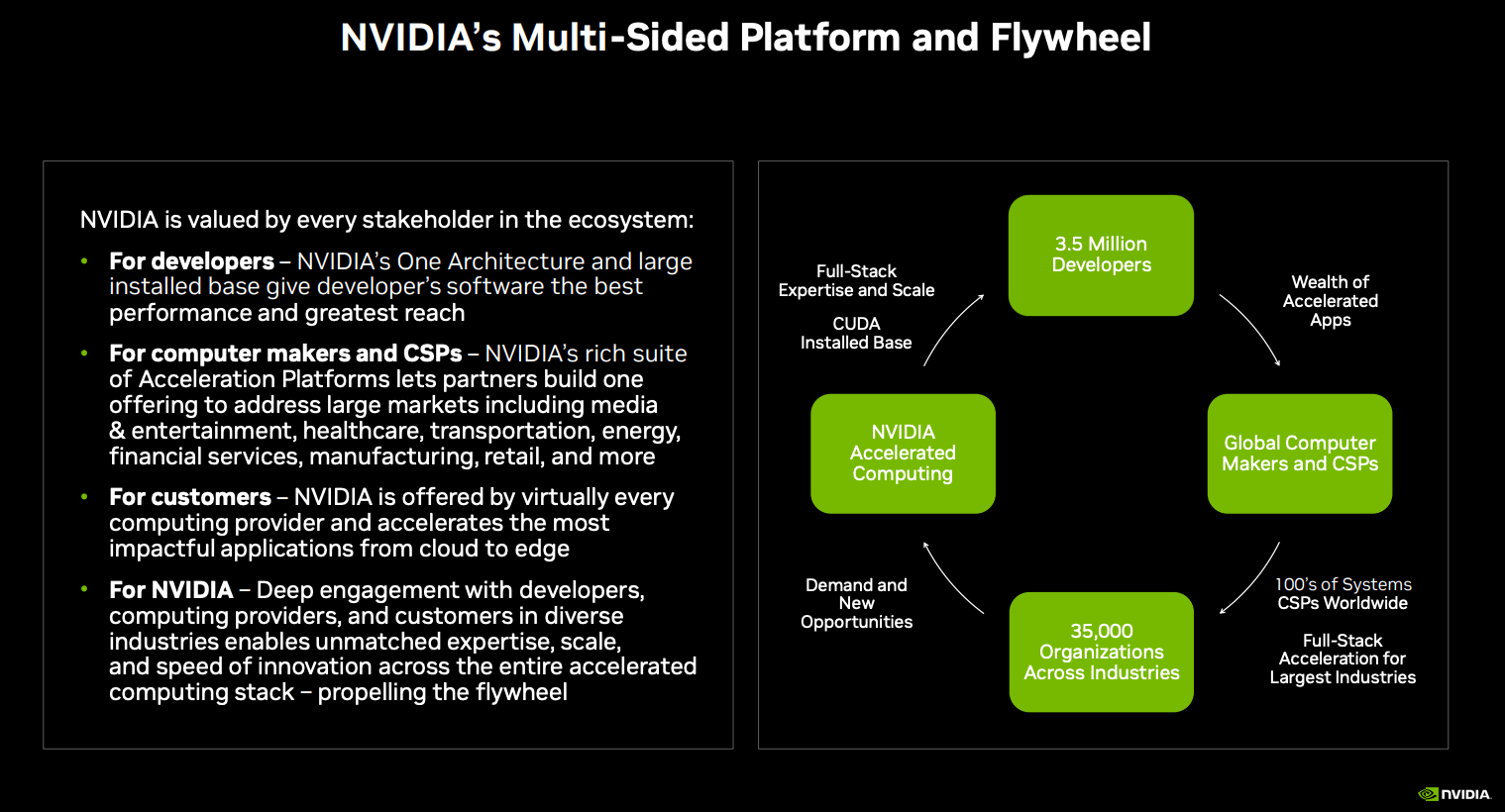
Multi-market platforms and their network moat
Nvidia’s first platform had three key players:
- Software developers: GPUs are specialized hardware and need highly skilled hardware programmers to code. However, CUDA’s brilliance is that it brings the convenience of software development to specialized hardware products. When they launched in ‘06, Nvidia went all in chasing them down and getting them accustomed to the platform—knowing they were essential to the platform flywheel.
- Hardware manufacturers: CUDA is all software, but it needs hardware to run with it. Jensen decided to keep this component closed, meaning only Nvidia Taiwanese-made GPUs can run CUDA. This turned out to be a fantastic move in (1) creating defensibility, and (2) providing superior performance to users as it allowed Nvidia to rapidly iterate on better designs and bring the best-in-class hardware-software integration to the developers.
- Consumers: This includes all the customer profiles who would need fast computing.
This creates a nice multi-sided platform and flywheel, with more demand for chips and systems driving more developers and organizations into the ecosystem, in turn, solidifying Nvidia’s network effect.

That flywheel was, and still is, fueled further by two other elements:
- Strong partnerships: Nvidia’s partnerships with other big tech companies (Microsoft, Amazon, IBM, etc.) are another competitive advantage. This was especially true in their GTM phase of CUDA, as it helped them reach new customers and markets. They’ve also partnered very closely with the game developer community, and this tight feedback loop has given them a massive advantage in the gaming industry, as is evident by Nvidia being the preferred choice by a landslide for game developers.
- Robust sales and distribution channels: Nvidia sells their chips through a bunch of channels, including direct sales, original equipment manufacturers (OEMs), and e-commerce platforms.
As mentioned,
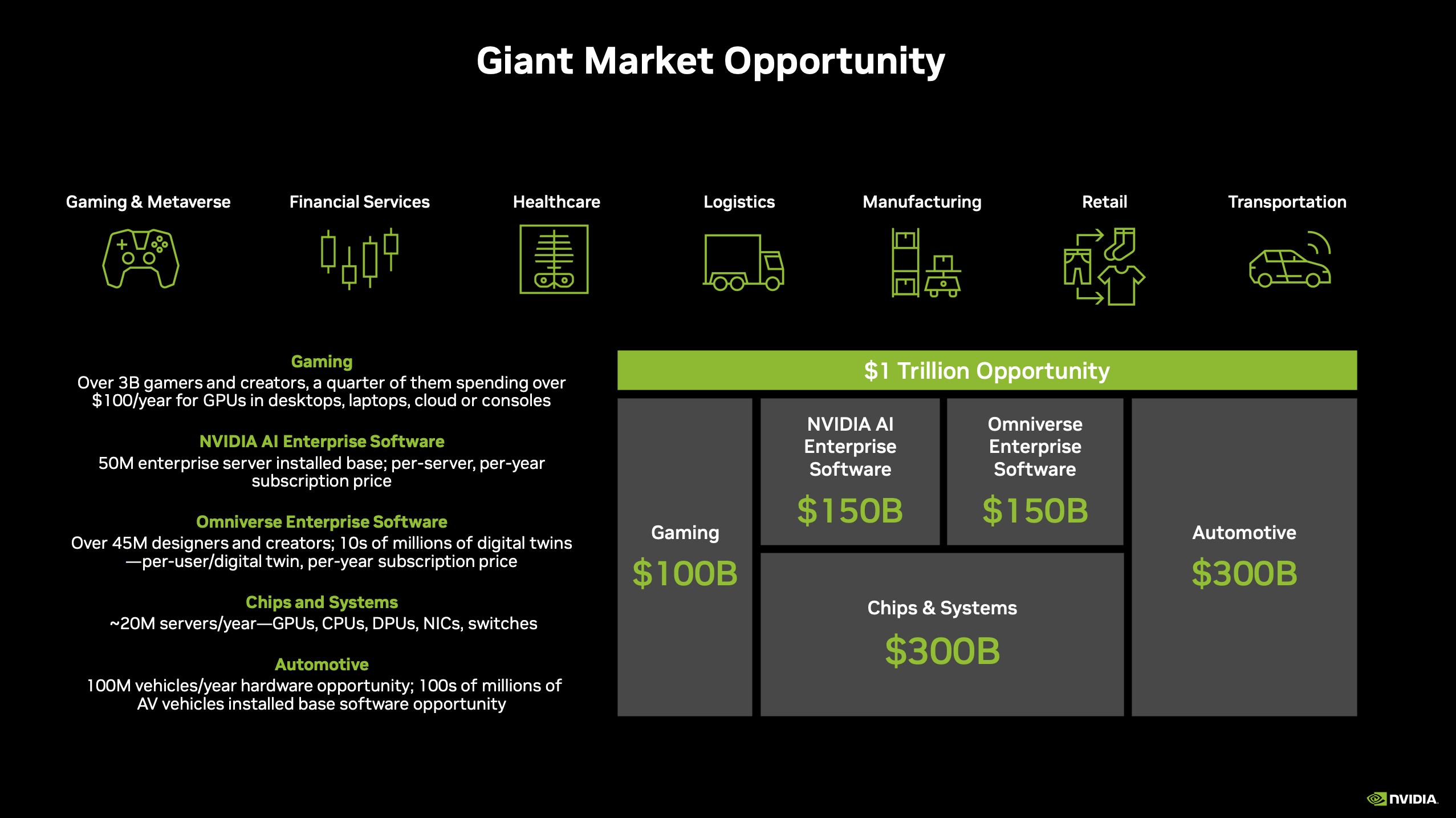
their CUDAxGPU platform was general-purpose, enabling Nvidia to cut across various verticals and tap into the growth of different emerging sectors. In other words, if an industry like crypto took off, they’d be well-positioned to ride that wave. And when looking at a few of the big domains that CUDA specializes in supporting at the moment—gaming, creative design, autonomous vehicles, robotics—it’s clear these all have a long runway for growth for decades to come.
AKA,
Nvidia is poised to provide for multiple gold rushes.
A testament to the power of solving hard problems in the background.

What you can do with this
When demand is up, build your position in the arena from a different point of view
Study the market to spot emerging opportunities, don’t rest on your laurels, and study your competitors to understand their most important strategic decisions.
Then build a coherent strategy based on the following:
- An understanding of where you are
- A different point of view about what the big opportunity ahead is
- An honest analysis of the challenges/problems that stand in your way
- A fair assessment of your internal capabilities, and your advantages
Ask yourself,
which industry rule can we challenge to generate a valuable, different position?
























 🫵
🫵